本地 AI 工作流
如何用本地 AI 模型运行 Claude Code,同时不破坏 llama.cpp KV Cache(持续更新)
本地后端(例如 llama.cpp、llama-server 和 LM Studio)在提示词开头保持稳定时最快。如果 Claude Code 不断加入变化的 metadata 或 git context,后端可能无法命中 KV cache,于是又要重新 prefill 大段 system prompt。下面这套设置的目标,就是让提示词前缀更稳定。
问题来源:Reddit LocalLLaMA PSA。
TL;DR:直接用这个版本。
1. 启动 llama-server
/path/to/llama-server \
--model /path/to/your-model.gguf \
--jinja \
--reasoning auto \
--threads 12 \
--n-gpu-layers 99 \
--flash-attn on \
--mlock \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--cache-ram 24576 \
--ctx-checkpoints 128 \
--checkpoint-every-n-tokens 1024 \
--slot-prompt-similarity 0.01 \
--host 127.0.0.1 \
--port 8080 \
--parallel 1 \
--cont-batching \
--metrics \
--slots如果你使用 TurboQuant build,可以把 value cache 改成:
--cache-type-v turbo42. 启动 Claude Code
ANTHROPIC_BASE_URL=http://127.0.0.1:8080 \
ANTHROPIC_API_KEY=no-key \
ANTHROPIC_MODEL=your-model.gguf \
CLAUDE_CODE_ATTRIBUTION_HEADER=0 \
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 \
DISABLE_TELEMETRY=1 \
DISABLE_ERROR_REPORTING=1 \
claude --bare \
--model your-model.gguf \
--dangerously-skip-permissions \
--exclude-dynamic-system-prompt-sections \
--settings '{"includeGitInstructions":false}' \
--allowedTools "WebFetch,Read,Edit,Write,Bash(curl:*)"核心思路:减少动态 prompt 变化,前缀复用就会更稳定,重复 prefill 更少,本地 Claude Code 实验也会更快。
本地测试结果
为了验证这套设置,我们在一台 Apple M3 Max MacBook Pro 上,用 Qwen3.6 27B 模型跑了实验。我们让 Claude Code 多轮生成一个单文件 HTML 五子棋(Gomoku)游戏,然后检查 llama-server 的 timing output、prompt-eval tokens 和生成速度,确认 cache 行为是否正常。
Claude Code 可以正常跑在本地 endpoint 上,而且 timing logs 显示:多轮请求里的 cache 问题已经被修复。

First request:
prompt eval time = 271184.95 ms / 34947 tokens
Next request:
selected slot by LCP similarity, sim_best = 0.989
restored context checkpoint
prompt eval time = 5136.44 ms / 441 tokensCache 证明:重复 prompt-eval 工作量从第一次请求的 34,947 tokens,降到下一次请求的 441 tokens;同时 llama-server 显示已经 restored the context checkpoint。
Perfect! 我们也检查了记录侧。即使 Claude Code 指向本地第三方 provider,而不是 Anthropic,DataMoat 仍然捕获到了 work trail、token breakdown 和 thinking tokens,包括 Claude Code UI 里看不到的细节。
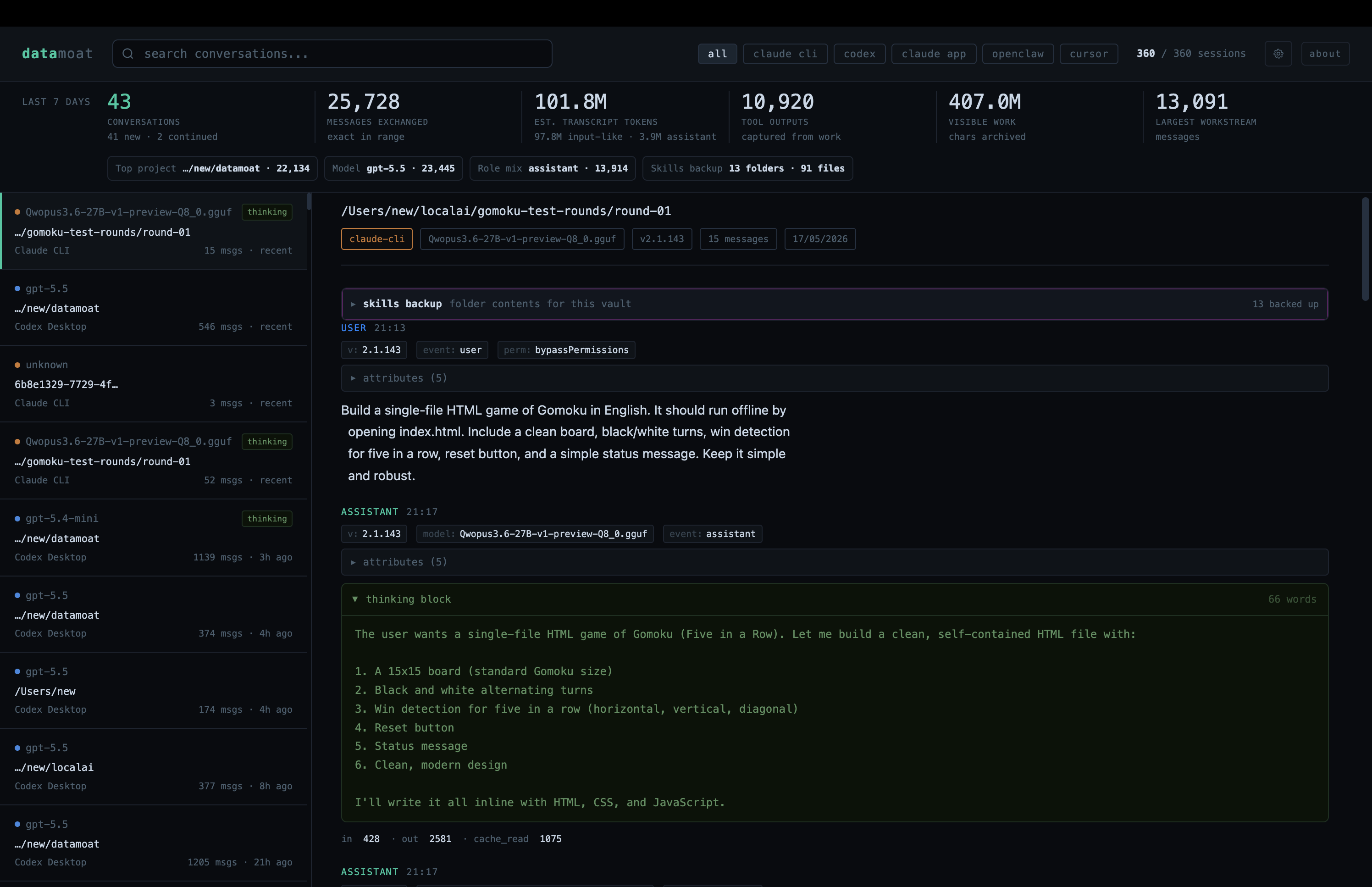
接着,我们测试 tool calling:让 Claude Code 打开 Chrome 并截一张图。
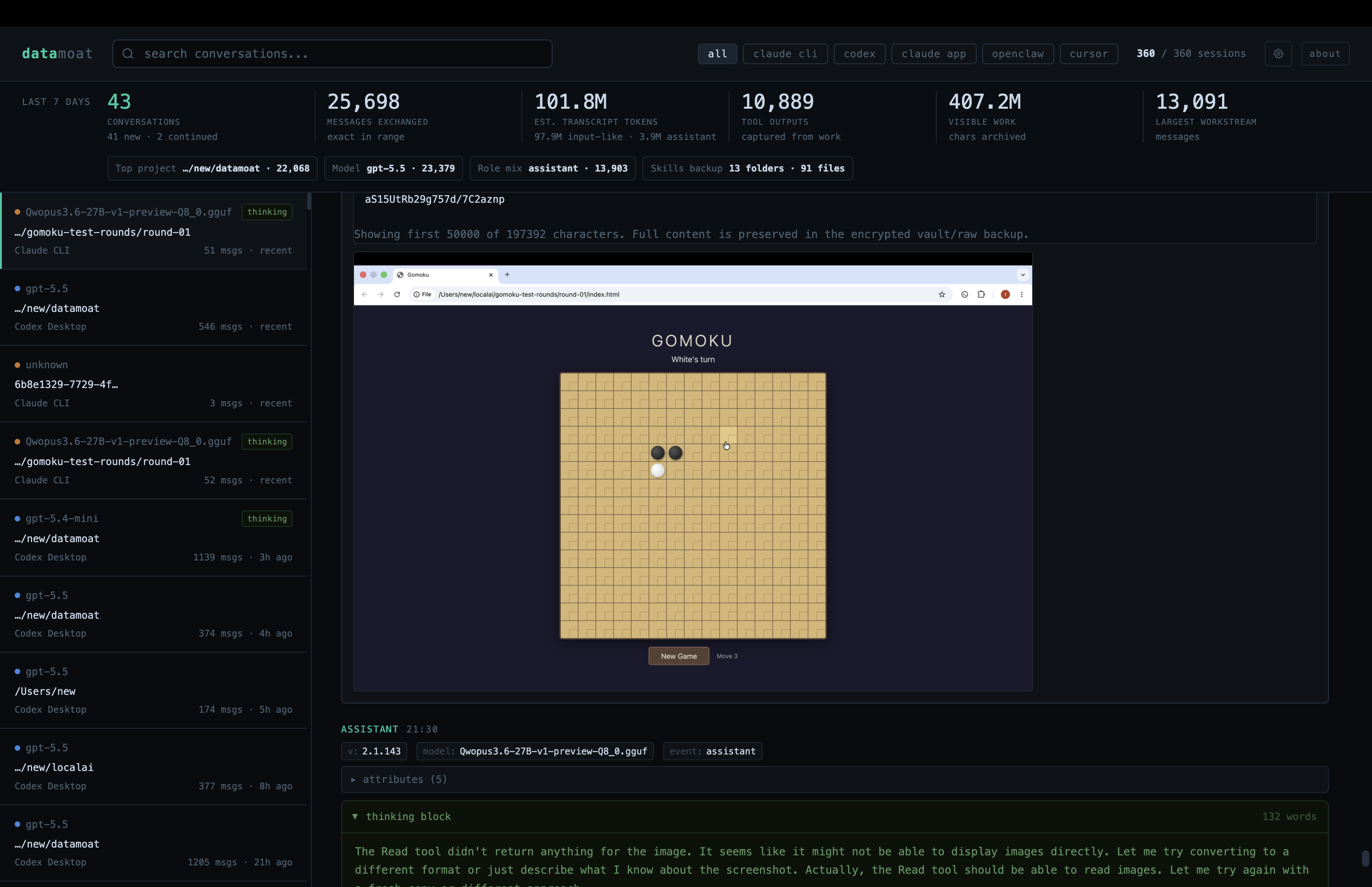
Amazing! 这说明在这套测试环境里,普通 coding turns 和 tool-calling turns 都能走通 cache 路径。
感谢阅读。我们会随着 llama-server、本地模型和 Claude Code 的变化持续更新这套设置。如果这些笔记有用,可以收藏或分享。